Why EU Policy Might be Targeting the Wrong AI Chokepoints
For more than a decade, cloud access has been one of the European Commission’s primary digital policy concerns, and this focus has recently intensified. On June 25, 2026, the Commission reached the preliminary view that AWS and Microsoft Azure should be designated as gatekeepers under the Digital Markets Act. Against this backdrop, this essay presents evidence from a discourse analysis of the developer community, which suggests that practitioners are not experiencing AI implementation hurdles at the level of cloud modalities. Rather, bottlenecks have shifted towards agentic orchestration, inference efficiency, and, partly, hardware issues. Europe’s structural deficits lie in the areas of energy costs and fragmented capital markets; is sovereign AI programme has stalled, creating new dependencies at the model level. Consequently, the “cloud chokepoint” theory of harm, which was compelling when first formulated, now rests on weakened premises, while the opportunity costs of misallocated regulatory attention are growing.
Introduction
Lately, the European Commission has moved on cloud computing with unusual speed. In November 2025, it opened three simultaneous market investigations under the Digital Markets Act (DMA): two to assess whether AWS and Microsoft Azure meet the threshold for gatekeeper designation, and a third to examine whether the DMA’s existing tools are adequate for the cloud sector more broadly. In June 2026, the Commission then preliminarily found that AWS and Microsoft Azure should be designated as DMA gatekeepers for cloud computing, despite falling below the quantitative thresholds, citing their entrenched user bases and switching costs. At the same time, it is organising thematic roundtables with industry stakeholders, covering interoperability, financial conditions, and contractual practices, with a final report due by May 2027. In parallel, the Cloud and AI Development Act – the centrepiece of the Commission’s recently unveiled “tech sovereignty” package – introduces a four-tier cloud sovereignty framework for public sector procurement.
Before the next enforcement priorities are locked in, it is therefore important to ask whether cloud is the actual bottleneck preventing Europe from competing in AI, and whether this degree of regulatory attention is (still) pointed at the right layer of the stack. As Thibault Schrepel notes, the DMA’s service-based taxonomy was designed for stable intermediation services, as it attaches durable obligations to categories that AI models traverse “faster than the regulatory cycle can track”. Any potential mismatch matters because the Commission is simultaneously hoping to drive AI uptake across the economy, with the Commission’s own “Apply AI” strategy calling for a step-change in enterprise AI deployment. In addition, the Commission must also manage an increasingly complex transatlantic relationship with a United States that remains indispensable to Europe’s security posture.
The market the regulators mapped, and how it changed
When European competition authorities began constructing the case for cloud market intervention some years ago, the picture appeared straightforward: Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform collectively held (and still hold) strong positions in infrastructure-as-a-service (IaaS), the basic provision of computing power, storage and networking over the internet. Switching costs were high. And in the early days of the “ChatGPT moment”, incumbents were aiming to vertically integrate into AI model development. On that reading, they seemed to fit the gatekeeper profile that the Digital Markets Act (DMA) was designed to address, which is why the Commission has recently convened multiple cloud computing roundtables under DMA auspices and provisionally designated AWS and Microsoft Azure as gatekeepers on June 25, 2026.
However, the designation process has sparked criticism, since neither provider meets the DMA’s standard quantitative thresholds. The Commission has instead relied on Article 3(8), which permits designation on the basis of a market investigation and a qualitative judgement about contestability and fairness. This pathway is explicitly contemplated by the Act, but it places a higher burden on the underlying market analysis. That analysis is contestable on at least two grounds. First, market structure: AWS holds approximately 28% of the IaaS market, Azure around 21%, and Google Cloud roughly 14% – all well below the 40% threshold below which the Commission itself considers dominance unlikely under Article 102 TFEU. Second, egress fees and interoperability barriers, which were the main concerns motivating the investigation, are already being addressed by the EU Data Act, which mandates cloud switching rights and phases out egress fees by January 2027.
However, the deeper problem is that this decision concerns a market where shares and respective roles are actively shifting rather than entrenching. The DMA was enacted to focus on markets “prone to tipping” towards a single dominant player. But there are many ways in which the AI value chain has disaggregated over the past two years: frontier model developers, fine-tuning infrastructure providers, inference optimisation layers, and application developers each operate with different compute sourcing strategies. The OECD’s November 2025 report on competition in AI infrastructure notes that the AI supply chain covers a range of markets each with their own unique dynamics, and cautions that competition authorities should closely monitor market developments. Several specialist GPU cloud providers, such as CoreWeave, Lambda Labs, and Crusoe Energy, as well as a growing number of sovereign and regional alternatives, have emerged as alternatives for AI training and large-scale inference. According to research by Copenhagen Economics (from August 2025), there are already more than 100 players offering access to accelerators (mostly GPUs) for generative AI workloads. While these providers do not compete across the full IaaS spectrum, they compete where competition is most needed for AI, often at prices below hyperscaler rates. In this context, note that the DMA’s gatekeeper logic rests partly on business users’ dependency on a platform to reach end users. But as specialist GPU cloud providers emerge, and as open-weight models make local deployment increasingly viable (see below), enterprise developers have a growing range of routes to market. Independent financial modelling of the AI economy confirms this disaggregation: by early 2026, the hosting layer’s share of deduplicated generative AI revenue had shrunk relative to apps and foundation models, with value “moving up the stack”.
To complement this picture, I draw on preliminary empirical evidence from an ongoing discourse analysis of AI developer communities, part of a broader CEP study planned for publication in the second half of this year. The study tracks IT community discourse across internet fora such as Hacker News and Reddit as well as major developer surveys to map where AI implementation is perceived as blocked and whether cloud provision remains an operational chokepoint. Via keyword tracking, the discourse analysis captures eight layers of the AI stack: Compute / Hardware (GPUs, chips), Cloud Provider (hyperscalers, specialist GPU-cloud providers, and inference API services, as well as framing around vendor lock-in and cloud exit), Base Model (model weights, fine-tuning, and model releases), Inference (serving runtimes, quantisation formats, cost optimisation), Orchestration (multi-step agentic workflows, including tool use), Data / Retrieval (vector databases and document processing), Observability (evaluation, monitoring), and Developer Tooling (AI-native code editors, prompt engineering, and deployment).
Before examining a current snapshot of this data, it is worth briefly explaining why this kind of evidence is important in a policy debate that has relied almost entirely on market share data and competition filings: The companies most exposed to potential disruptions in the AI supply chain are the tens of thousands of small and medium-sized enterprises across Europe that are currently navigating their own AI transformation, including traditional firms automating their back-office workflows, or startups building on top of foundation models. In order to increase Europe’s competitiveness, these businesses depend on a functioning AI stack. To understand where they actually get stuck, it is more informative to look at where their developers ask for help. For this preview of the larger study, I draw on three pieces of data: Hacker News, a widely read technology forum used heavily by developers and engineers; Reddit communities (such as “r/MachineLearning” and “r/LocalLLaMA”), which provide a continuously updated record of where technically sophisticated practitioners encounter friction; and the responses from developers in a large-scale survey from 2025.
Figure 1: Temporal shift in AI stack discourse (Hacker News and Reddit, 2022–2026)
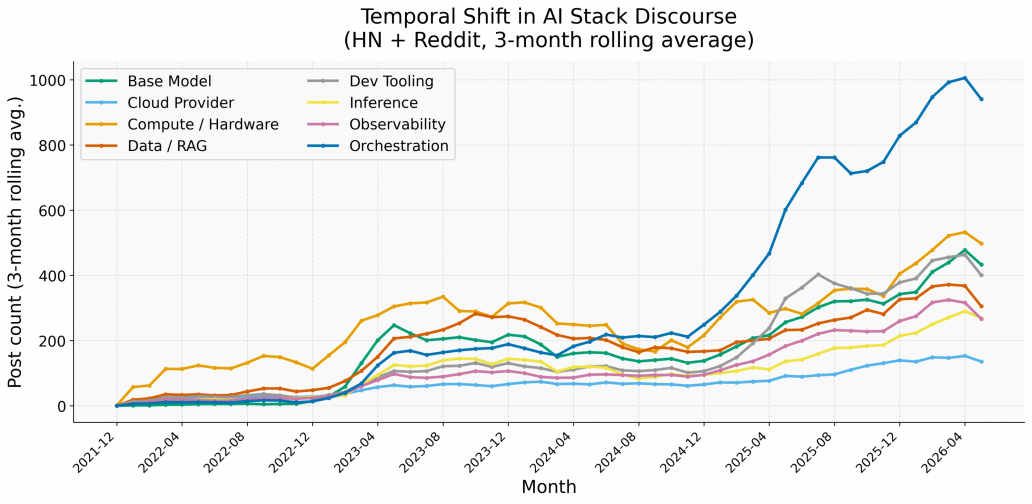
Taken together, these empirical data, analysed via Natural Language Processing (NLP), suggest that cloud provision or cloud switching is not where practitioners report getting stuck (Figure 1). Tracking discussion volume across the different layers of the AI stack from 2022 to 2026, “Cloud Provider” discourse has remained the flattest of all categories, growing modestly from roughly 50 to 150 posts per month on a 3-month rolling average (although there is some rise in the related “Compute / Hardware” discourse). At the same time, “Orchestration”, i.e. the layer concerned with coordinating AI agents and models to complete tasks, has exploded from near-zero to over 1,000 posts per month since early 2025. Discussions about problems related to “Dev Tooling” have followed a similarly steep trajectory. The layers that practitioners identify as bottlenecks have shifted decisively toward agentic orchestration, inference efficiency, and, partly, hardware issues.
A word on what “orchestration” means in this context, since this category has seen the steepest rise and the term can be misunderstood. In the developer discourse tracked here, orchestration friction refers mainly to the difficulty of building reliable multi-step workflows in which AI models and agents must coordinate. This involves managing tool calls, maintaining context across steps, handling probabilistic model outputs, and avoiding error propagation. The bottleneck is primarily the non-deterministic, unreliable behaviour of AI systems themselves, rather than any chokepoint in the underlying infrastructure. This distinction matters for policy: the finding is not that orchestration requires regulatory intervention next, but that the operational challenges developers actually face are nowadays mostly upstream of the cloud layer, in the model and application tiers.
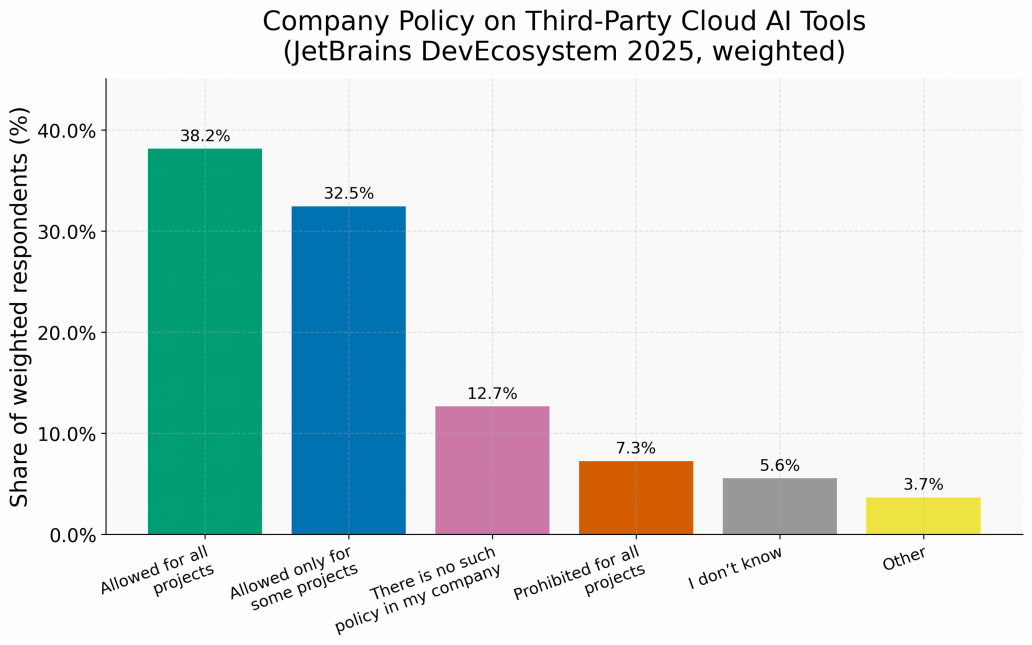
The survey evidence points in the same direction. In 2025, JetBrains asked 24,534 developers about their organisations’ policies on third-party cloud AI tools. Over 70% work in environments where such tools are either fully permitted or permitted for specific projects; only 7.3% report an outright prohibition (Figure 2). Whatever cloud providers’ pricing and licensing practices mean in competition law terms, they are not translating into a widespread experienced barrier to AI access among the developer community. It bears emphasis that this practitioner evidence does not speak to the legal question of market dominance, which turns on structural features and legal doctrine. What it does address is the prior empirical question: whether the enforcement theory maps onto the market as it currently operates for the practitioners who depend on it.
Figure 2: Company policy on third-party cloud AI tools, JetBrains DevEcosystem 2025 (weighted)
Looking forward towards the mid-term future, two structural shifts might further disrupt the AI cloud market and reduce potential barriers. First, there is the growing success of local AI systems, that is models deployed on-device or on private infrastructure rather than through hyperscaler APIs. Research indicates that such locally-run models now answer approximately 71.3% of real-world chat and reasoning queries accurately, compared to 23.2% in 2023. Despite the gigantic investments associated with the leading labs in the US, open models are only 6-9 months behind proprietary frontier models, a trend that has been going on since 2023. If this development continues, the majority of AI workloads will not route through hyperscaler cloud APIs at all. Even Chinese start-ups, such as DeepSeek, are increasingly following in the footsteps of their US counterparts by building their own data centres. Among self-selecting model-routing users on OpenRouter, token share is shifting towards open-weight models. As open and locally deployable models close the capability gap with frontier systems at a fraction of the cost, the premise that cloud IaaS constitutes a chokepoint for AI access becomes arguably harder to sustain. Secondly, research on decentralised AI training suggests that even the compute layer, long considered the most intractable centralisation point, may be less of a structural bottleneck than current enforcement assumptions imply. A series of algorithmic breakthroughs, particularly low-communication optimisers such as DiLoCo and its variants, have slashed the bandwidth requirements for coordinating model training across geographically distributed nodes.
The gap between enforcement theory and the competitiveness problem
What implications does this evidence have for the governance of a rapidly evolving AI stack? The DMA’s ex-ante obligations were designed on the basis of years of accumulated competition case law, which developed for market structures that pre-date the current AI transformation. In particular, the legal architecture of the DMA produces three specific mismatches with AI development: its data obligations fragment the cross-contextual data flows on which model quality depends; its interoperability duties assume stable access points that agentic AI resolves at runtime; and its self-preferencing rules assume the ranking of pre-existing items rather than the generation of new ones. In other words, the Act is written around specific practices and technologies that are now changing rapidly.
With respect to the cloud layer, the experience in the UK provides an instructive lesson: Having produced a detailed market investigation, the CMA Board in March 2026 declined to open strategic market status (SMS) investigations into AWS and Azure for cloud infrastructure, accepting voluntary commitments on egress fees and interoperability instead (while simultaneously opening a separate SMS investigation into Microsoft’s business software ecosystem). The CMA’s judgment on cloud IaaS was that market developments had changed the priority calculus. So far, European regulators seem to have drawn the opposite lesson: The Commission still pursues cloud cases and its first review of the DMA resisted calls for more fundamental structural revision, taking the position that the Act remains “fit for purpose”.
The deeper AI problem in Europe is structural. The Commission’s own 2026 State of the Digital Decade report confirms that the EU holds only 9% of the global semiconductor market, far from its 2030 target of 20%. The same can be said of computing capacity: Although the deployment of edge nodes is on track to meet the 2030 Digital Decade target, the capacity of computing still lags significantly behind demand. Plans for AI Gigafactories – large-scale shared computing facilities designed to give European firms access to frontier training infrastructure – have been recently scaled back. At the same time, evidence for a growing compute constraint keeps accumulating: in March 2026, Anthropic tightened peak-hour session limits for paying users due to capacity constraints, and by May had agreed to spend $1.25 billion per month renting capacity from a direct competitor (xAI’s Colossus cluster) through 2029.
In short, scarcity at the infrastructure layer is real, but it is primarily a buildout problem, not a regulatory problem. Europe’s response to this increasing computing scarcity, which might hurt its firms during the AI transformation, should be to become an attractive host for that infrastructure. This requires resolving the barriers to buildout, such as slow planning and permitting processes as well as fragmented capital markets. Moreover, as the recent spat about Anthropic’s Mythos model made clear, Europe also requires – at least for the short term – access to frontier AI models for defensive purposes. Catching up on the AI model layer, and speeding up AI deployment and experimentation, is where policy attention is needed most urgently. The Mythos episode also supports the argument for open cloud marketplaces and the resilience that comes from multi-model, multi-provider architectures. Disruption to a single model does not eliminate a customer’s AI capabilities when the underlying platform offers several options. However, Europe’s compute buildout has so far focused primarily on training infrastructure, but widespread AI adoption generates persistent demand for inference serving: distributed, low-latency, user-proximate.
Conclusion and policy recommendations
Regulatory instruments should be calibrated to the actual structure of markets as they currently exist. In this respect, the Commission should conduct a layer-specific market assessment of AI infrastructure. Preliminary evidence from developer community discourse suggests that practitioners now identify agent orchestration, AI inference, and hardware issues as the key operational constraints, not cloud provision or cloud switching. These are fast-moving, competitive areas. With locally run models set to handle the majority of routine AI workloads in the near future, and research into decentralised AI training making progress, the scope of any cloud chokepoint may narrow. More generally, Europe must find a way to make digital regulation more dynamic and flexible. Static enforcement frameworks applied to dynamic markets produce over-intervention in some areas and under-intervention in others. For instance, the DMA was calibrated to specific practices that the AI transformation is now partly rendering obsolete. The CMA’s experience illustrates the value of a responsive regime, pointing to a potential revival of ex post, instead of ex ante, enforcement. Finally, the Commission should treat European compute buildout as a strategic instrument for geo-political leverage. To achieve sufficient compute capacity for AI diffusion and experimentation, energy costs, permitting processes and capital market fragmentation must be addressed with urgency.

Copyright Header Picture: shutterstock


